MSS = main stream science
TBP = The Thunderbolts Project team
DLaP = David LaPoint (Primer Fields)
WT = Wal Thornhill of TBP
It is to their great credit that the guys at Thunderbolt (TBP) are promoting an electric universe model. They do a great job attributing an electrical cause to the cosmological observations rather than the current empirical gravitational model.
WRC has a more detailed approach, because WR goes further down the rabbit hole to incorporate the metaphysical/spiritual aspect into a meaningful philosophy which explains the true Cause of these physical phenomenon. The TBP do not consider the Creator is intimately involved with every aspects of its Creation.
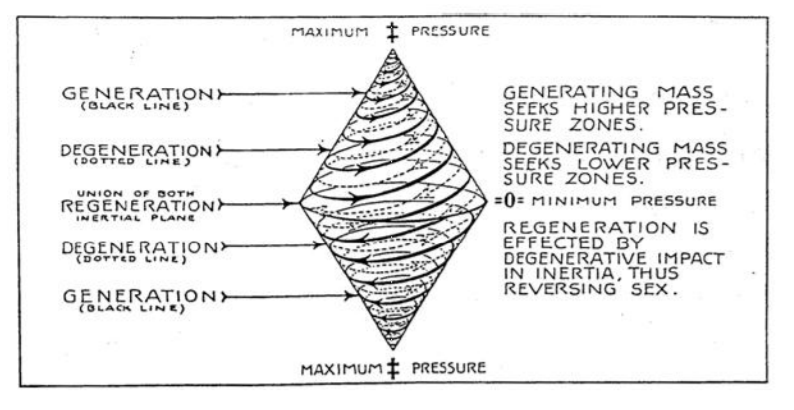
Although the TBP researchers are performing sterling work they do unfortunately carry too much MSS baggage into their work.
Too much credence is given to the standard view of free electrons running in plasma. While Birkland currents may be a true observation free electrons cannot be their cause.
In addition to this, WT only develops his theories to a certain point allowing widely held MSS dogma such as a force of gravity to also play a part in the overall EU. This might be a valid result if the TBP offered a theory of the electrical cause of those gravitational observations.
 The TBP initial starting point is that plasma is the fundamental state of matter. It is fair to say, that WRC winds the electric universe model right back to establish the bridge which connects the metaphysical to the physical universe.
The TBP initial starting point is that plasma is the fundamental state of matter. It is fair to say, that WRC winds the electric universe model right back to establish the bridge which connects the metaphysical to the physical universe.
As trained physicists, I guess the TB project members find it difficult to fathom, that there could be a Creator who directly influences all observed phenomena within the physical universe, and that there is no energy in matter.
As Einstein suggested, there is an Intelligent Cause to the observed effects.
Solids when heated create a liquid. When liquids are heated create a gas. When a gas is heated it creates a plasma. It is described as a condition whereby the electrons are free to move, and as such a plasma has the ability to carry an electric current. A plasma is thus an ionized gas. If the universe is then filled with this plasma the universe can be considered as an electric field, with visible and non-visible currents running in all directions. Some may describe this omnipresent plasma as the ether, a condition required by Maxwell.