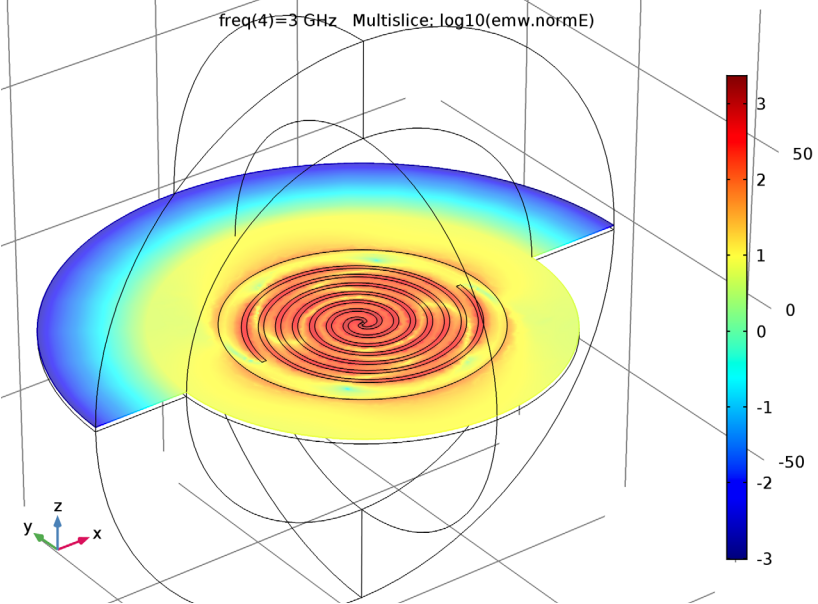
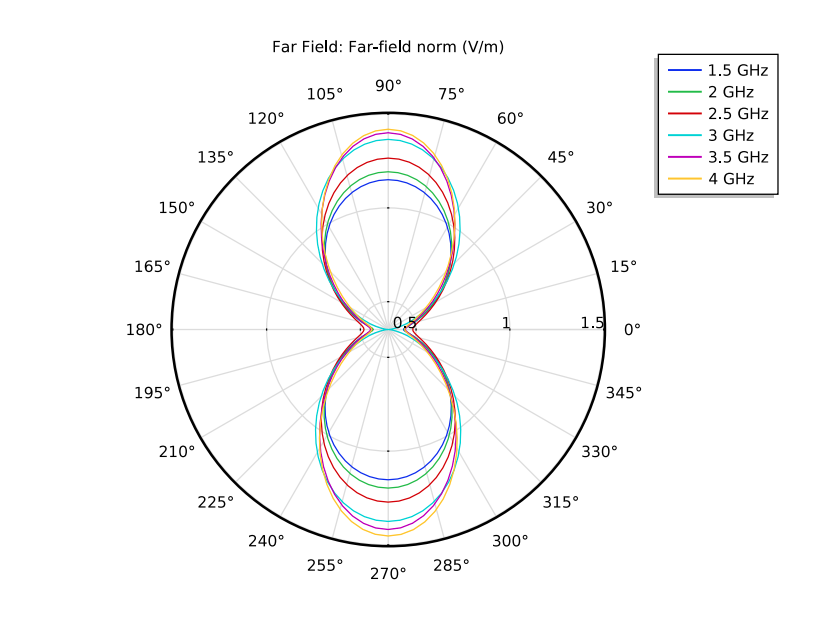
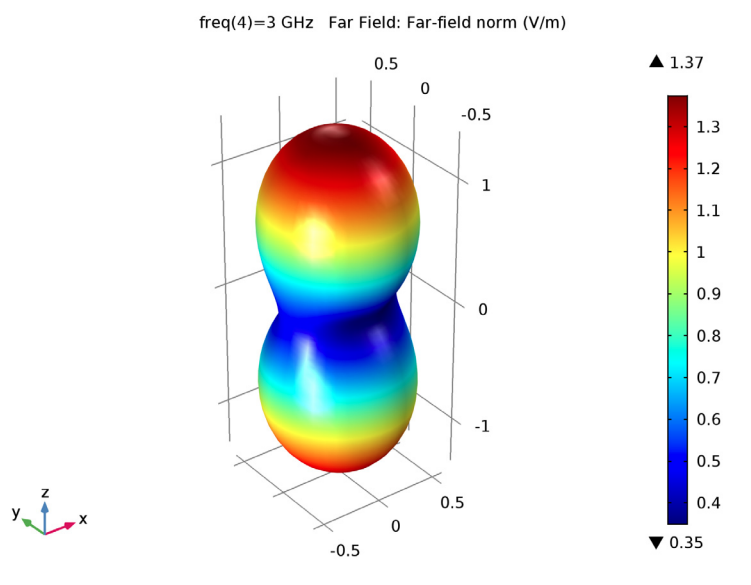
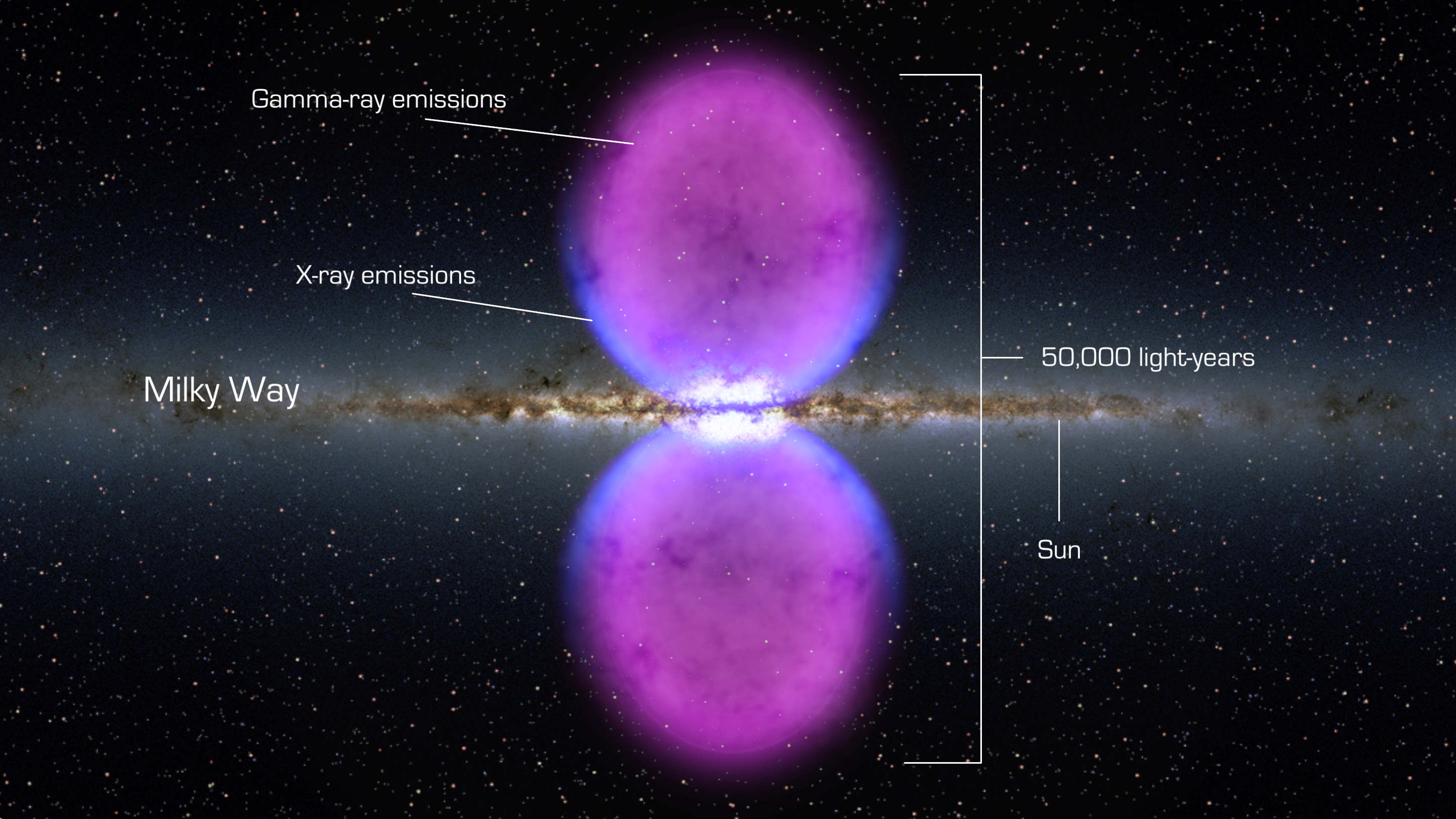
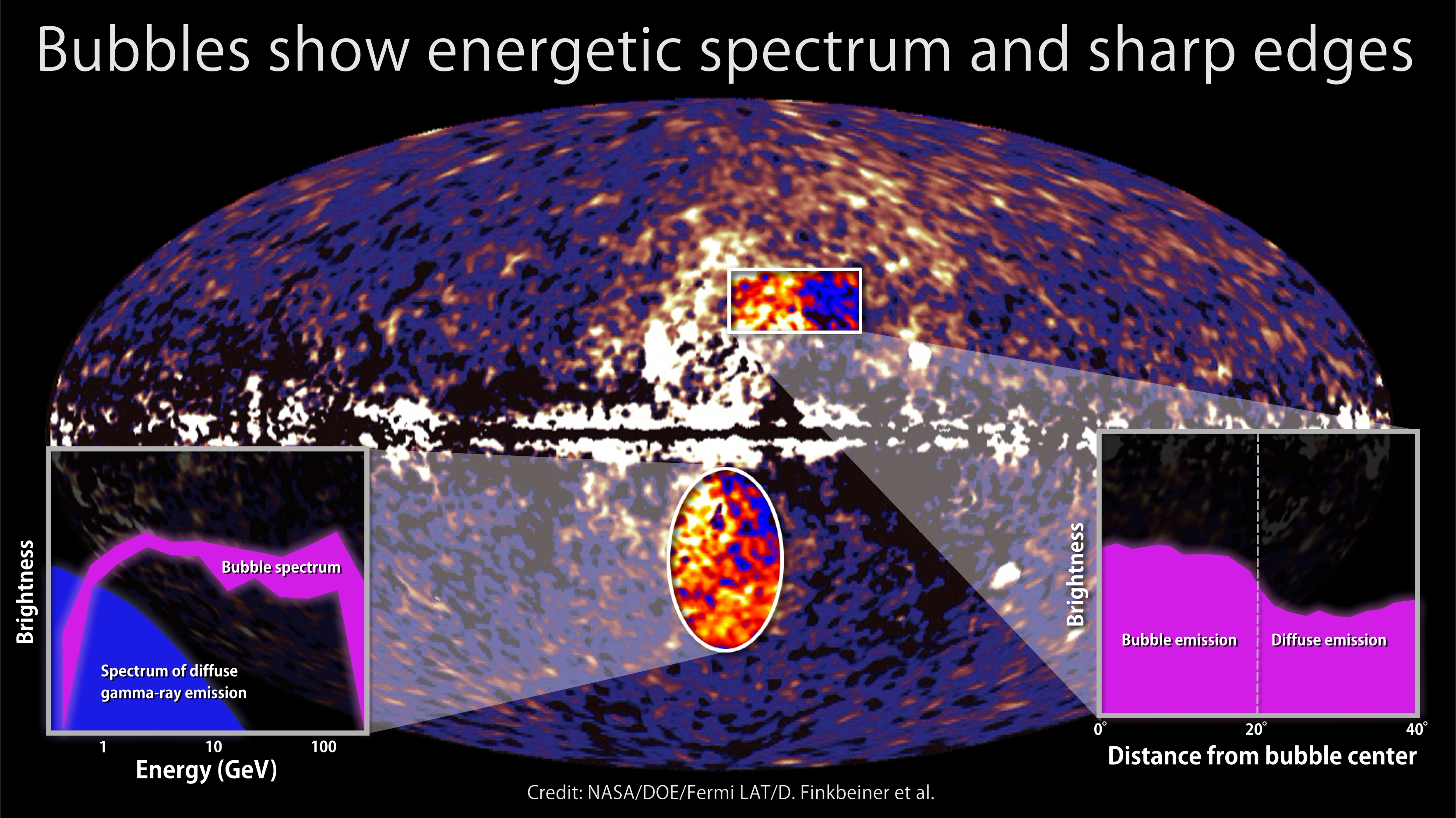
Posted on May 19, 2020May 19, 2020Ken Wheeler – Space and CounterSpace ref: Spiral Slot Antennas with Electromagnetics Simulation – Fermi Space “Structure”